
Almost too easily, I've become addicted to Claude Code. Not just as a coding assistant—it literally makes decisions for me. It chooses the architecture, picks the library, refactors my code, and I just hit Enter. AI models are no longer just perceiving the world; they're acting in it.
And once an AI is making decisions rather than just predictions, the notion of "reliability" has to shift with it. It's no longer enough for an AI to simply admit when it's stumped. In high-stakes environments like autonomous driving, a system can't just throw up an error message and stop in the middle of the highway.1 It needs to understand, adapt, and make (safe) decisions, even in situations it has never encountered before.
This post explores that shift: from reliability as epistemic awareness to reliability as robust generalization, and the emerging paradigm of reasoning and world models that makes it possible.

The Reliability Shift: From "Knowing What You Don't Know" to Generalization
Historically, AI reliability has focused on epistemic awareness: teaching models to identify when they are operating outside their training data. Techniques like anomaly detection and out-of-distribution (OOD) detection are great for knowing when to trust a model's output.
However, for an autonomous agent, knowing it's confused is only half the battle. The ultimate goal is scaling generalization: the ability to perform reliably on novel, unseen data. We don't just want a self-driving car to detect a rare obstacle; we want it to understand the situation and navigate around it safely.
To achieve this level of reliability, we need to move beyond models that simply memorize linguistic patterns. We need agents that can transform a problem into a sequence of logical steps (i.e., operators that are generalizable and robust). This brings us to the core of the emerging paradigm: reasoning.
This post examines the recent shift toward reliable AI through three pillars: (1) reasoning in Vision-Language-Action models, (2) the theoretical case for learning generalizable "operators," and (3) the rise of world models as rich environments for agent learning.
Pillar 1: Reasoning in Vision-Language-Action (VLA) Models
A prime example of this recent approach is NVIDIA's Alpamayo-R1, a Vision-Language-Action (VLA) model designed for autonomous driving. Instead of directly mapping inputs to actions, Alpamayo-R1 employs a "Chain of Causation" (CoC) reasoning process.
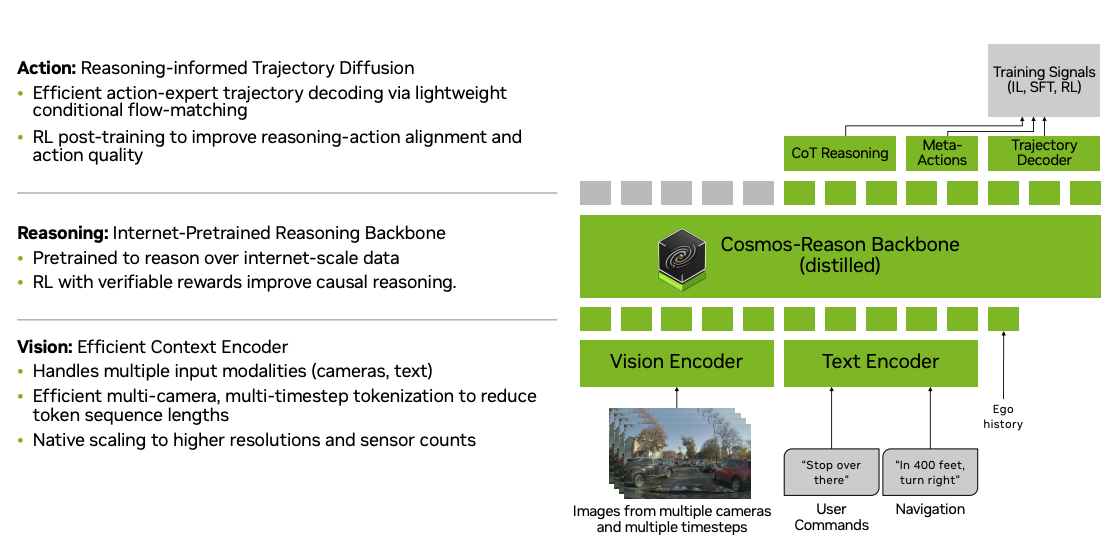
By breaking down a complex driving scenario into a logical chain of cause and effect, the model can better understand the "why" behind its decisions. This structured reasoning process significantly improves the agent's ability to handle long-tail, safety-critical scenarios that were previously difficult to generalize to.
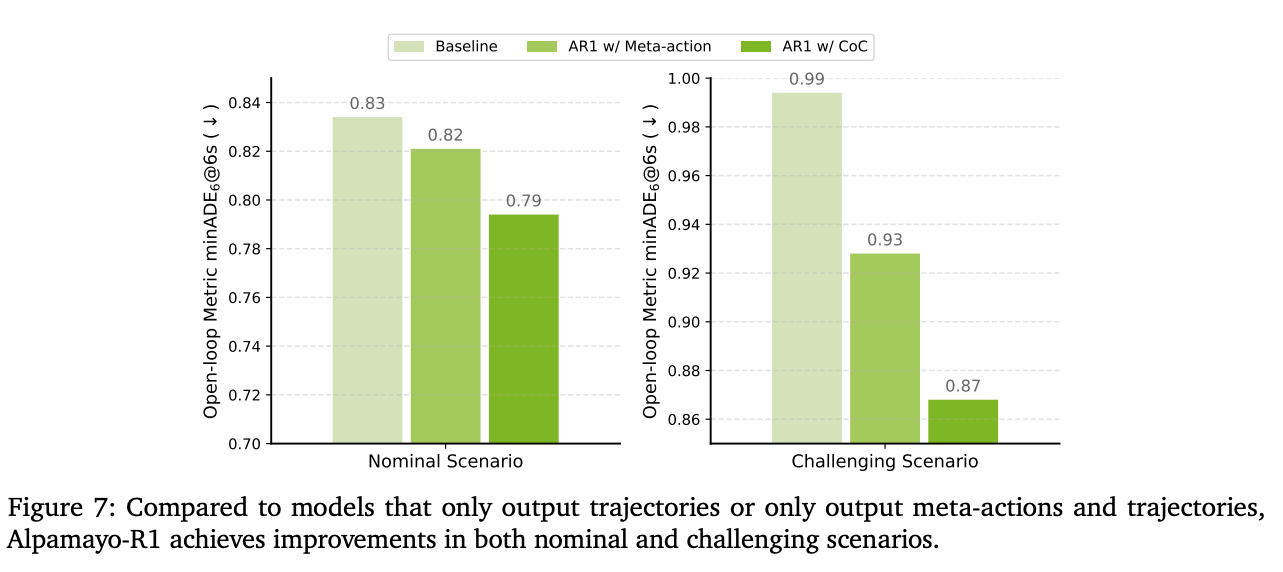
Pillar 2: The Theoretical Case for Learning "Operators"
Why is this explicit reasoning step so crucial? Theoretical analysis of Transformer architectures provides one of the most compelling answers. A key insight from recent research is that trying to learn complex problems end-to-end (without intermediate steps) is often computationally inefficient and prone to failure on out-of-distribution data. For instance, researchers found it is not trivial to teach a model multi-hop reasoning QA.2
Consider the following example:
Q. Marco is taller than Patricia. Bob is taller than Marco. Sara is taller than Bob. Peter is taller than Sara. Is Marco taller than Sara?
Instead of forcing a model to memorize specific answers (e.g., "No" in the previous example), research reveals we should focus on teaching it operators (e.g., chaining comparisons: Sara > Bob > Marco, so No)—the fundamental logical building blocks of reasoning. When a model learns how to think rather than what to answer, it can apply that knowledge to an infinite number of new situations. This is the essence of true generalization.
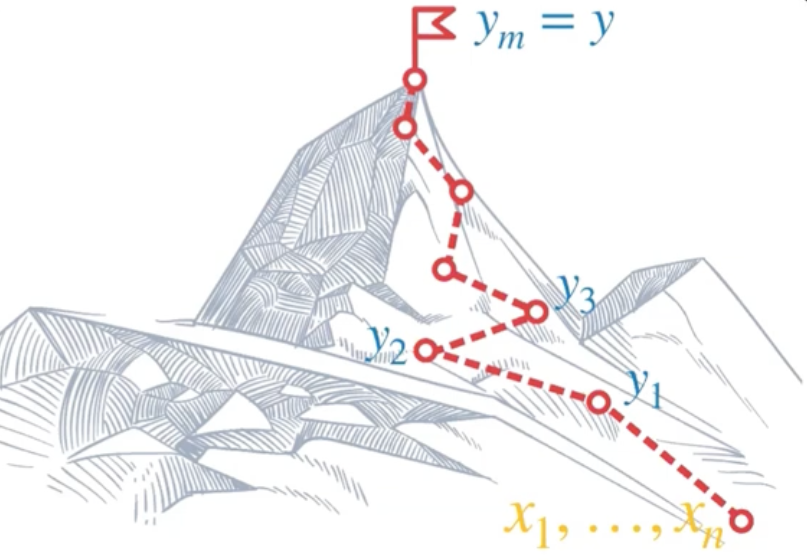
Therfore, it's important to teach "how" and "when" to reason, rather than "what" to reason. Consequently, the model can break down a question into logical steps that it is able to reliably solve.
Pillar 3: The Rise of World Models
Another piece of the puzzle for reliable AI is giving our reasoning agents a rich playground in which to learn and test their skills. This is one of the key areas where world models come in. While the concept of simulating the world for planning and control isn't new, modern video-generation-based world models have recently garnered massive attention (see, for example, Genie 3 by Google DeepMind).
These advanced simulators can enhance reliability by providing a more comprehensive test bed. For example, they can generate vast amounts of synthetic uncommon data, such as driving in blinding rain or snow, which is crucial for robust training and evaluation. Moreover, they enable on-policy training by allowing the AI agent to explore within the world model simulator.
Companies like Waymo are building world model simulations that can generate out-of-distribution driving scenarios. Similarly, Tesla uses world model simulations to re-evaluate new policy models on historical issues by reproducing the scenario within the simulator.
What's Next: Open Questions
It would be valuable to explore the source of the model's performance gains in Alpamayo. Does training with reasoning fundamentally improve the backbone's latent representation of the physical world, or is the explicit test-time "Chain of Thought" generation strictly necessary for the performance boost?
We must evaluate whether the model can be fine-tuned or distilled to output direct actions without the reasoning steps while still maintaining its robust OOD performance. If the backbone itself has become stronger (and distillation is successful), this might indicate that collecting reasoning data is an efficient and robust way to rapidly scale up the pre-training or early SFT warm-up post-training stages. This is also important from the perspective of efficient inference, as we could opt out of reasoning steps if they turn out not to be explicitly needed during test time.
On the other hand, if explicit reasoning is revealed to be essential, future research may focus further on improving reasoning quality with even deeper thinking.
In principle, the goals of World Models and Reasoning VLAs are the same. They both aim to create AI models (or backbones) that truly "understand" how the world operates. As Alibaba's RynnVLA noted, next-world prediction can improve VLA performance when jointly trained. In other words, well-trained world models may serve as robust backbones for VLAs.
Alternatively, we can first prompt VLAs to generate reasoning along with potential future scenarios, then feed these into world models to roll out and simulate each scenario. By evaluating these rollouts based on physical feasibility and likelihood, we can make more reliable final action decisions. On a related note, this underscores the importance of building world models that not only simulate plausible futures but also provide calibrated likelihoods of their generations. For instance, if prompted to imagine a dragon flying onto the road, the model should recognize such a scenario as physically infeasible rather than treating it as equally plausible as realistic outcomes.
In a similar sense, an important question will be how to explore within the world model simulator. One of the most critical features of a world model is that it can take action inputs as prompts. As many path-planning algorithms do, we not only need a state transition model—p(xt+1 | x1:t, u1:t)—but we also need an efficient method to improve the planned trajectory (e.g., via a path-integral controller) by refining the control inputs u1:t (iteratively).
Note that, this is a highly relevant topic regarding test-time scaling in agentic LLMs, and I believe these questions will soon encompass physical AI as well.
Closing Thought
We are witnessing a convergence: reasoning gives AI the ability to decompose novel problems, operator-learning provides the theoretical foundation for why this generalizes, and world models offer the simulation environments to train and validate these capabilities at scale. The path from "knowing what you don't know" to "handling what you've never seen" is the defining challenge for the next generation of reliable AI—and I'm excited to be working on it.
1 In fact, even in my nominal Claude experience, it's a hassle when I find Claude stopping and waiting for my confirmation (Yes/No) to proceed with actual commands. It has gotten to the point where the AI is the decision-maker and I'm the rubber stamp. ↑
2 Of course, recent LLM models are already more than smart enough to solve IMO math problems. But remember, GPT-4 in early 2024 still failed to perform simple arithmetic calculations. ↑
References
- Wang, Y., Luo, W., Bai, J., Cao, Y., Che, T., Chen, K., ... & others. (2025). Alpamayo-r1: Bridging reasoning and action prediction for generalizable autonomous driving in the long tail. arXiv preprint arXiv:2511.00088.
- Abbe, E., Bengio, S., Lotfi, A., Sandon, C., & Saremi, O. (2024). How far can transformers reason? the globality barrier and inductive scratchpad. Advances in Neural Information Processing Systems, 37, 27850-27895.
- Cen, J., Huang, S., Yuan, Y., Li, K., Yuan, H., Yu, C., ... & others. (2025). Rynnvla-002: A unified vision-language-action and world model. arXiv preprint arXiv:2511.17502.